一、核心架構圖覽與總覽
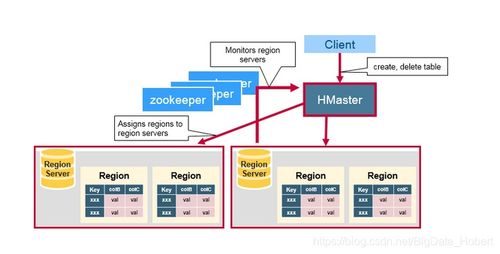
HBase是一個構建在Hadoop文件系統(HDFS)之上的分布式、可擴展的NoSQL數據庫。其架構設計旨在實現海量數據的實時讀寫訪問。一張清晰的架構圖通常包含以下核心層次與組件:
- 客戶端層:提供Java API、REST API、Thrift等接口,供應用程序訪問。
- ZooKeeper:作為分布式協調服務,負責管理集群狀態(如主HMaster選舉)、元數據入口(-ROOT-和.META.表位置)以及RegionServer的心跳監控。
- HMaster:管理節點,負責表管理(創建、刪除、修改)、Region分配與負載均衡、RegionServer故障轉移。通常高可用部署。
- RegionServer:工作節點,負責處理數據的讀寫請求,管理多個Region。
- Region:數據表的分區,是負載均衡和數據分布的基本單位。一個表最初只有一個Region,隨著數據增長會自動分裂。
- Store:每個Region按列族(Column Family)劃分為多個Store。
- MemStore:每個Store包含一個內存寫緩存,寫入數據首先順序寫入HLog(WAL),然后放入MemStore,排序后批量刷新到磁盤。
- HFile:存儲在HDFS上的底層數據文件,是SortedMap的持久化格式,包含索引以加速查詢。
- HDFS:作為底層存儲,提供數據的高可靠性和高可用性。
數據流向:寫請求 -> ZooKeeper(獲取元數據)-> RegionServer -> HLog(預寫日志)-> MemStore -> 定期刷寫為HFile存儲于HDFS。讀請求則可能合并MemStore和多個HFile的數據。
二、架構組件深度解析
1. HMaster:指揮官
- 職責:非數據路徑節點,主要負責元數據管理和集群調度。
- 表操作:DDL語句的執行者。
- Region管理:監控RegionServer,在啟動、故障或負載不均時,負責Region的分配、遷移與合并。
- 高可用:多個HMaster通過ZooKeeper選舉出Active Master,備用者處于待命狀態。
2. RegionServer:主力工兵
- 核心服務單元:每個節點運行一個RegionServer進程,通常與HDFS DataNode同機部署以減少數據網絡傳輸。
- Region托管:托管多個Region,處理這些Region的所有IO請求。
- 組件構成:
- BlockCache:讀緩存,采用LRU策略,緩存頻繁訪問的數據塊。
- MemStore:寫緩存,每個列族對應一個,數據在內存中按行鍵排序。
- HLog (WAL):預寫日志,每個RegionServer一個,確保數據持久性。寫操作先日志后內存,防止MemStore數據丟失。
- 刷寫與壓縮:定期將MemStore數據刷寫(Flush)為新的HFile到HDFS;后臺進程對多個小HFile進行合并壓縮(Compaction),優化讀取性能并清理刪除標記。
3. Region與數據模型
- 數據邏輯視圖:表(Table) -> 行鍵(RowKey) -> 列族(CF) -> 列限定符(Qualifier) -> 時間戳(Timestamp) -> 值(Value)。
- 物理存儲:表按行鍵范圍水平分割為多個Region。每個Region內,數據按列族物理存儲,同一列族的所有列存儲在同一個Store中。
- Region分裂:當Region大小達到閾值,會自動分裂為兩個,由HMaster重新分配,實現水平擴展。
4. ZooKeeper:神經中樞
- 協調者:維護集群配置信息,實現分布式鎖和選舉機制。
- 關鍵作用:
- 存儲HMaster和RegionServer的注冊信息與活躍狀態。
- 存儲所有Region的尋址入口(-ROOT-表位置,現已簡化,但元數據路徑仍由其管理)。
- 監控節點故障并通知HMaster。
5. HDFS:堅實底座
- 持久化存儲:所有HFile、HLog最終存儲在HDFS上,享受其自動多副本(默認3份)帶來的容錯能力。
- 數據本地性:RegionServer盡量調度到存儲其對應HFile副本的DataNode上,實現“移動計算而非數據”,提升讀性能。
三、HBase在信息系統集成服務中的應用與集成指南
在構建企業級信息系統集成平臺時,HBase常作為海量結構化/半結構化數據的存儲與實時查詢引擎。
1. 典型應用場景
- 用戶畫像與行為日志:存儲用戶的點擊流、交易記錄、屬性標簽,支持實時查詢和批量分析。
- 物聯網時序數據:存儲設備傳感器上報的帶時間戳的數據,行鍵設計可包含設備ID與時間戳逆序。
- 消息與訂單歷史:存儲在線系統的歷史消息、訂單狀態變更,供查詢追溯。
- 內容管理系統的元數據與索引。
2. 集成模式與最佳實踐
- 數據管道集成:
- 寫入端:通過Kafka等消息隊列承接業務系統數據,由Spark Streaming、Flink或自定義客戶端寫入HBase,實現流式入庫。
- 讀取端:提供REST/Thrift接口服務層,封裝HBase Java API,供前端或微服務調用。可使用Phoenix提供SQL化查詢層。
- 與Hadoop生態集成:
- 批量分析:使用MapReduce、Spark直接讀取HBase數據進行離線分析,結果可寫回HBase或HDFS。
- 數據同步:通過Sqoop與關系數據庫進行批量導入導出;使用Canal/Apache NiFi進行近實時同步。
- 設計要點:
- 行鍵設計:這是最重要的設計決策,影響數據分布和訪問性能。需考慮散列性、有序性以滿足掃描和熱點規避需求(如加鹽、哈希、反轉)。
- 列族設計:不宜過多(通常1-3個),因為每個列族獨立存儲,跨列族的事務和掃描效率低。將訪問模式相似的列放在同一列族。
- 版本與TTL:合理設置數據版本數和生存時間,實現自動過期清理。
- 預分區:提前根據行鍵范圍創建多個Region,避免初始單Region熱點和后續自動分裂帶來的性能波動。
3. 運維與監控考量
- 監控體系:集成HBase原生Metrics(對接Ganglia、Prometheus)及HBase Web UI,關注Region分布均衡性、請求延遲、Compaction隊列、BlockCache命中率等核心指標。
- 高可用保障:確保HMaster、ZooKeeper集群的高可用部署;規劃RegionServer的滾動重啟與擴容流程。
- 備份與恢復:利用HBase Snapshot進行快速元數據與數據備份,或使用Export/Import工具。
四、
HBase的架構巧妙結合了LSM-Tree的寫優勢和HDFS的存儲可靠性,通過分層(客戶端、協調層、主控層、存儲層)和分片(Region)設計實現了水平擴展與高性能。在信息系統集成服務中,它扮演著大數據存儲與實時服務的核心角色。成功的集成不僅需要理解其架構原理,更需在數據模型設計、訪問模式匹配、生態工具鏈整合及運維監控上深入實踐,方能構建出穩定高效的數據基石。
(注:本文旨在提供全面的架構解析與集成指引,實際部署與設計應結合具體業務需求與集群規模進行。)